
刚一条句子让wordpress bug了,拆成两篇算了
for的终极取代:多线程混合编程
我们也常会遇到并不能简答并行化的情形,例如针对数组元素的复杂的操作。这时的一个选择就是混合编程: mex, 它可以实现matlab与C/C++/Fortan之间的相互调用。matlab自带的user guide里有详细介绍。
在这里我们讨论两个小trick. 首先注意到向量化的高斯核代码中我们用到了exp(A),A可能是一个非常大的矩阵。而matlab却会不谙风情的先将这个大矩阵在内存里复制一次,然后再逐一算exp. 有时我们明明算好内存能存下,但matlab却报out of memory了。
我们可以用C来对内存进行直接操作。例如for(i...){A(i)=exp(A(i));}. 不过还有另外一个问题:现在我们计算机大多是多核多线程,matlab也很早就支持了多线程加速,而简单的for只会单线程,所以mex后的代码可能会慢很多。这时的我们的一个选择就是openmp,它为共享内存的多线程提供了非常方便的实现。
下面附上一计算exp(A)的多线程代码,它无需额外内存:
#include "mex.h"
#include
#include
#include
using namespace std;
void mexFunction( int nlhs, mxArray *plhs[],
int nrhs, const mxArray*prhs[] )
{
double *A, *pp;
mwSize n, m, p, i, j;
A = mxGetPr(prhs[0]);
n = mxGetN(prhs[0]); // # of rows in C
m = mxGetM(prhs[0]); // # of columns in C
p = omp_get_num_procs();
#pragma omp parallel for private (j) \
default(shared) num_threads(p)
for (i = 0; i < n; i ++) {
for (j = 0; j < m; j ++)
A[i*m+j] = exp(A[i*m+j]);
}
return;
}
编译时需要稍修改下编译参数来开启openmp的支持。例如linux下gcc需要加上flag-fopenmp,详见此说明,Windows下的visual studio的相应的flag是/openmp.
但用这段代码时需要很小心。matlab使用了lazy copy的技术,既当我们运行命令A=B时,matlab不会立即将B复制一份给A, 只有当A或者B被修改的时候才执行复制。如果我们用上面代码对B做指数运算,例如mex_exp(B), 这时matlab不知道B变了,所以复制还是不会执行,那么A就会和B一起被修改了,这也许会给后面的代码造成麻烦。
代码究竟慢在哪里
我们可以方便使用tic,toc来知道每段代码的执行时间。但要知道每条语句的详细运行情况的话,非profile莫属。
先运行profile on,再运行需要测试的代码,然后使用profile viewer来查看报告。例如,上面两段不同的计算高斯核的实现的profile报告如下(为了报告更有信息,将其中的一条长语句拆开成了三句)。


根据报告我们就知道每条语句的执行情况,从而可以对其中时间耗费最多的部分进行优化。
无止尽的优化
大多人类活动就是一优化过程。无论是金钱,利益,地位,还是算法,代码,编译,硬件。但除了最优化外,我们还追求一些其他。例如我们用matlab是为了实现和调试上的方便,虽然优化能让计算机做得更快,但是却花去了我们的工作时间,而且使得代码难读懂。糟糕的实现是大忌,过度的优化也不可取。所以,我们需要在计算时间,开发时间,代码的可读性之间做一个权衡。
 . 但如果我们想用”外加”呢?既
. 但如果我们想用”外加”呢?既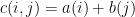 . 这时我们可以用
. 这时我们可以用 . 当然可以用双重for实现(如果第一直觉是用三重for的话…)。
. 当然可以用双重for实现(如果第一直觉是用三重for的话…)。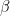 是样本之间的平均距离,既
是样本之间的平均距离,既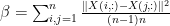 , 此时我们可以使用下面的代码:
, 此时我们可以使用下面的代码: 来处理罚,这里我们直接考虑最小化损失+罚的形式,既
来处理罚,这里我们直接考虑最小化损失+罚的形式,既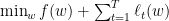 (罚前的参数
(罚前的参数 在这里写进了
在这里写进了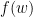 里了)。注意到罚
里了)。注意到罚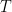 块,从而不能直接对每块做梯度下降得到online gradient descent. 于是我们转向dual problem.
块,从而不能直接对每块做梯度下降得到online gradient descent. 于是我们转向dual problem. 
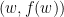 表示,每一条切线可由斜率
表示,每一条切线可由斜率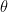 及与y轴交点,记为
及与y轴交点,记为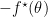 ,来确定。前一种表示是函数的primal form, 而后者则被称之为
,来确定。前一种表示是函数的primal form, 而后者则被称之为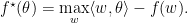
 .
. 
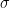 -强凸(
-强凸( 和
和 , 有
, 有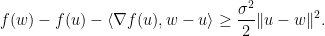
 之类,此乃后话了。
之类,此乃后话了。
 是
是 . 对任意的向量序列
. 对任意的向量序列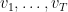 , 记
, 记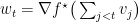 。那么对任意的向量
。那么对任意的向量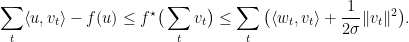
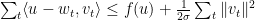 . 注意到
. 注意到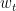 只和比
只和比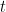 小
小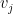 相关,所以我们可以取
相关,所以我们可以取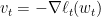 ,立即由
,立即由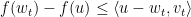 . 同前记
. 同前记 是离线最优解,且假设
是离线最优解,且假设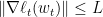 , 联立上面两不等式有,
, 联立上面两不等式有, .
.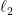 罚,那么
罚,那么 , 且
, 且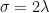 . 如果
. 如果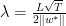 ,则有
,则有 , 这里
, 这里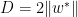 是对子空间
是对子空间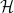 直径的一个估计。与上节Online Gradient Descent的regret bound比较,他们一样!
直径的一个估计。与上节Online Gradient Descent的regret bound比较,他们一样!
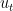 , 那么拉格朗日形式就是
, 那么拉格朗日形式就是 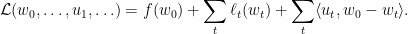
 ,记为
,记为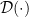 . 套进Fenchel conjugate的定义,就有
. 套进Fenchel conjugate的定义,就有
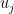 都是0, 从而只更新
都是0, 从而只更新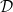 .
. 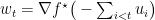 ,在收到数据的label后,选择
,在收到数据的label后,选择

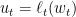 ,就是意味着维持最小但使得理论分析成立的步伐长度。我们也可以使用更加激进的步伐,
,就是意味着维持最小但使得理论分析成立的步伐长度。我们也可以使用更加激进的步伐, ,来最大限度的增加dual以期望收敛更快。不过这样通常使得每一步的计算开销更大。所以是仁者见仁智者见智了。
,来最大限度的增加dual以期望收敛更快。不过这样通常使得每一步的计算开销更大。所以是仁者见仁智者见智了。 。事实上,对于强凸的目标函数,目前已知最优的regret bound是
。事实上,对于强凸的目标函数,目前已知最优的regret bound是 。记得在OGD中我们使用固定的
。记得在OGD中我们使用固定的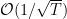 的学习率,如果我们将其改成变长的
的学习率,如果我们将其改成变长的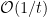 ,那么变可以达到这个最优上界。对于这节介绍的方法,我们可以通常将罚
,那么变可以达到这个最优上界。对于这节介绍的方法,我们可以通常将罚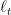 , 这样前
, 这样前 -强凸,从而达到使用变长学习率的效果。具体可见Shai的
-强凸,从而达到使用变长学习率的效果。具体可见Shai的 的损失是
的损失是 ,于是这个时刻Weighted Majority(WM)损失的期望是
,于是这个时刻Weighted Majority(WM)损失的期望是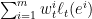 ,是关于这
,是关于这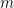 个专家的损失的一个线性组合(因为权重
个专家的损失的一个线性组合(因为权重 关于
关于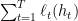 ,如果挑选
,如果挑选 的策略集
的策略集 关于
关于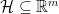 。
。 ,如果新的
,如果新的
 是
是 关于
关于 是学习率,
是学习率,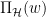 是投影子,其将不在
是投影子,其将不在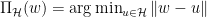 。此算法通常被称之为 Online Gradient Descent。
。此算法通常被称之为 Online Gradient Descent。
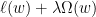 )的形式。例如
)的形式。例如 罚,
罚, 的限制下最小化
的限制下最小化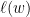 。
。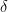 是一一对应的关系。实际上
是一一对应的关系。实际上 ,时就是一个半径为
,时就是一个半径为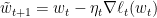 ,以及offline最优解
,以及offline最优解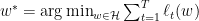 。因为
。因为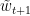 投影只会减少其与
投影只会减少其与 。简记
。简记 ,注意到
,注意到

 ,对
,对 。记
。记 ,且对所有
,且对所有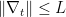 成立(既Lipschitz常数为
成立(既Lipschitz常数为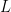 ),再取
),再取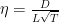 ,那么
,那么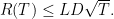
 ,这可以是一封邮件,或者一个样本。learner然后从策略集
,这可以是一封邮件,或者一个样本。learner然后从策略集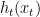 。learner然后收到正确答案
。learner然后收到正确答案 。
。 来衡量learner在
来衡量learner在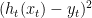 。为了方便起见,简记为
。为了方便起见,简记为 ,有
,有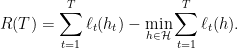
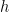 ,而如果我们每次都能选很好的
,而如果我们每次都能选很好的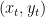 ,可能总损失会更小。但这非常难。因为我们是要定好策略
,可能总损失会更小。但这非常难。因为我们是要定好策略 是不是随着
是不是随着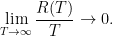
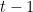 轮一直是给正确答案的专家们,然后采用他们中多数人给出的那个答案。
轮一直是给正确答案的专家们,然后采用他们中多数人给出的那个答案。 是前
是前 是这些专家的个数。如果learner在时刻
是这些专家的个数。如果learner在时刻 。因为完美专家的存在,所以
。因为完美专家的存在,所以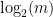 次变小机会,所以learner最多有
次变小机会,所以learner最多有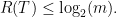
 ,对其维护一个信任度
,对其维护一个信任度![w^i\in[0,1]](https://s0.wp.com/latex.php?latex=w%5Ei%5Cin%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) ,且使得满足
,且使得满足 。在
。在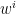 的概率挑选专家
的概率挑选专家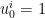 . 在
. 在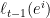 ,来做如下调整:
,来做如下调整:
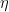 是学习率,越大则每次的调整幅度越大。然后再将
是学习率,越大则每次的调整幅度越大。然后再将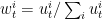 。此算法被称之为Exponential Weights或者Weighted Majority。
。此算法被称之为Exponential Weights或者Weighted Majority。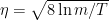 ,那么
,那么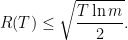
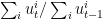 ,其上界是关于最优策略的损失,下界是关于learner的损失,移项就得regret的上界(online/stochastic算法的收敛性分析大都走这种形似)。具体的证明这里略过,后面后补上文献。
,其上界是关于最优策略的损失,下界是关于learner的损失,移项就得regret的上界(online/stochastic算法的收敛性分析大都走这种形似)。具体的证明这里略过,后面后补上文献。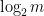 增到了
增到了 。这两者在实际的应用中有着很大差别。例如我们的目标是要使得平均regret达到某个数值以下,假设前一种方法取1,000个样本(迭代1,000次)就能到了,那么后一种算法就可能需要1,000,000个样本和迭代。这样,在时间或样本的要求上,前者明显优于后者。类似的区别在后面还会更多的遇到,这类算法的一个主要研究热点就是如何降低regret,提高收敛速度。
。这两者在实际的应用中有着很大差别。例如我们的目标是要使得平均regret达到某个数值以下,假设前一种方法取1,000个样本(迭代1,000次)就能到了,那么后一种算法就可能需要1,000,000个样本和迭代。这样,在时间或样本的要求上,前者明显优于后者。类似的区别在后面还会更多的遇到,这类算法的一个主要研究热点就是如何降低regret,提高收敛速度。
Recent Comments