
Primal-dual的观点
《红楼梦》第三一回云:天地间都赋阴阳二气所生。世间有阴便有阳,在优化界也是如此。我们将需要最小化的目标函数称之为primal problem. 其对应就有dual problem. 例如常见的Lagrange Duality. 如果primal是凸的,那么dual便是凹的。且在常见情况下,最小化primal等价于最大化dual. 有时候直接求解primal problem很麻烦,但dual却方便很多。或是通过考察dual problem的性质能得到最优解的一些性质。一个经典的案例就是SVM.
上节我们通过子空间投影
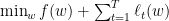

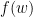
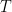
Shai Shalev-Shwartz提出可以用Fenchel Duality来研究其对偶式。Shai最近在online/stochastic界相当活跃。虽然和他不熟,不过因为他姓比较长,所以下面亲切的用Shai来称呼他。Shai 毕业于耶路撒冷希伯来大学,PHD论文便是online learning. 然后他去了online learning重地TTIC, 更是习得满身武艺,现在又回了耶路撒冷希伯来大学任教。他的数学直觉敏锐,善于将一些工具巧妙的应用到一些问题上。
两个概念
对一个凸函数,如下图所示,我们可以用两种不同的描述方式。一种就是函数上的所有点,函数曲线变由这些点构成;另外一种是每一个点所对应的切线,此时函数由所有切线形成的区域的上边缘确定。

函数上每一个点可由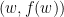
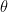
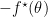
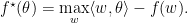
既然我们称它们为primal-dual, 当然意味着可以相互转换。实际上,对于一个闭凸函数,有

另外一个概念是关于函数凸的程度的。一个函数被称为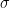


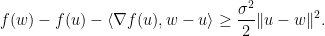
示意图如下。直观上来说就是这个凸函数要凸得足够弯。这个定义可以拓展到一般的范数和次导数上来处理诸如稀疏罚

Regret Bound分析
使用这两个概念可以得到一个重要定理。假设

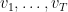
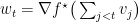
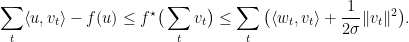
此定理可以为Boosting, learning theory里的Rademecher Bound提供简单的证明,不过我们先关注它在online上的应用。不等式两边左右移项得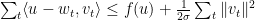
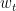
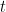
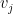
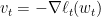
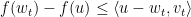

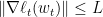

如果我们用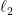

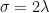
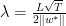

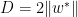
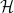
一般化的online算法
不小心先把理论讲完了,下面来解释下算法。接回一开始我们谈到的要考虑dual problem. 先观察到primal problem可以写成

引入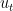
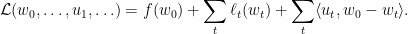
这样dual problem就是最大化函数

注意到与primal problem不同,这时罚里面的变量也被拆成了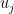
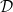
总结下算法。在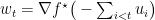

下面是一个示意图。在每个时间里我们根据新来的数据不断的增大dual, 同时使得primal变小。

一个值得讨论的是,在这里我们可以控制算法的aggressive的程度。例如,如果我们每次只取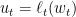

这个算法框架可以解释一系列算法,例如前面提到的Halving, 它使用激进步伐,或是WM, 使用平缓的步伐,以及Adaboost. 当然,我们可以从这个算法框架里推出新的有no-regret保证的新的online算法。
到这里,我们介绍的三个算法(前面是Online Gradient Descent, Weighted Majority)的regret bound都是



21 comments
Comments feed for this article
04/10/2011 at 4:28 am
shuai
老兄,写得很牛哇,关注
04/10/2011 at 6:56 am
dumtal
挺有意思的。不过我以前碰到过nonconvex, nor concave的问题,就比较棘手了。如果是convex minimization,其实问题是简单的。当然,如果能改进速度,自然是很好的。但是至少这个问题不是NP-hard的。
最近读了一些stochastic approximation的理论(见Kushner & Yin, 2003),最简单的例子是Robbins-Monro alg.,也可以用来作online learning。 不知道跟你介绍的算法有什么关系么?
04/10/2011 at 6:25 pm
Mu
non-convex是一个困难的问题,因为不能保证找到global optimal solution。实验上来说就是每次结果都不一样。例如k-means,大家公认它对初始值敏感。
machine learning比较喜欢用convex来近似non-convex,例如用l_1对l_0罚近似,square loss/hinge loss对0-1loss近似。最近大家考虑的nonconvex函数的submodular functions,例如Francis Bach NIPS’10
用stochastic approximation来做online learning的分析算是一种标准手段,见Leon Bottou的文章以及他在mlss的talk
04/15/2011 at 12:46 pm
Chonghai Hu
submodular function也是做convex的吧,话说Bach的文章每篇都是精品呀,这篇NIPS10也不例外,的确解决了非常有意义的一些问题,Bach这几年在sparse领域做得风生水起呀,佩服佩服。
04/16/2011 at 9:00 am
Mu
可以用来做做0norm这种非凸的东西。m jordan的学生,现在已经俨然是一个山头了
04/17/2011 at 7:38 pm
dumtal
恩。只不过我的问题不是machine learning的问题。无法那么简单的来近似,还要考虑其实际意义。
global optimization并不是那么困难,有些问题如果有好的性质是可以解的,只不过速度没有convex的那么快而已。当然,大部分都是NP-hard。
我的意思是如果一个问题是convex的,那基本上就是能解的,当然解法有很多种,但都是细枝末节不同罢了。stochastic approximation还是蛮有意思的框架。我想online learning逃不出这个框架吧。
04/17/2011 at 10:32 pm
Mu
你那块的模型当然更复杂,所以考虑的应该主要是建模,求解只要不要慢到不能忍就行吧。
online的theory这块发展还不久,所以考虑的只是convex的情况。如果不关心theory的话,online还是很多解non-convex的算法,例如neural network也可以算一online算法嘛。
stochastic approximation确实很强大。但online能不能逃出它就不是清楚了,毕竟不同的框架带来不同的理论。实际work的算法总能从各种框架找到解释。例如adaboost,既能从online learning,又能从max margin。
04/10/2011 at 7:46 am
mli-漫谈在线学习:阴阳论 | 丕子
[…] 上交Mu Li同学的博文,转至此。做学问,总要写出点东西来才行,我还是停留在转载的地步,说明什么问题?1、没有做学问(嗯,最近在准备英语)2、做学问不深入不思考,没有自己的见解。 […]
04/10/2011 at 2:03 pm
漫谈在线学习:阴阳论☯ (via Large Learning) « Masonzms's Blog
[…] 四月 10, 2011 漫谈在线学习:阴阳论☯ (via Large Learning) Posted by masonzms under Research Leave a Comment Primal-dual的观点 《红楼梦》第三一回云:天地间都赋阴阳二气所生。世间有阴便有阳,在优化界也是如此。我们将需要最小化的目标函数称之为primal problem. 其对应就有dual problem. 例如常见的Lagrange Duality. 如果primal是凸的,那么dual便是凹的。且在常见情况下,最小化primal等价于最大化dual. 有时候直接求解primal problem很麻烦,但dual却方便很多。或是通过考察dual problem的性质能得到最优解的一些性质。一个经典的案例就是SVM. 上节我们通过子空间投影来处理罚,这里我们直接考虑最小化损失+罚的形式,既(罚前的参数在这里写进了$latex f(w … Read More […]
04/11/2011 at 11:34 am
漫谈在线学习3:阴阳论 | 增强视觉 | 计算机视觉 增强现实
[…] 转自MuLi的博客 […]
04/13/2011 at 8:38 pm
TransMatrix
Hi, 那在dual form里进行迭代,与直接在primal form里梯度下降想必,有什么好处呢?我看了Shai的paper,理论很有意思,但是不知道从primal-dual角度看能带来什么advantage
04/16/2011 at 8:58 am
Mu
关键是看谁方便。直接对primal做梯度下降也没问题,就如online gradient descent
04/15/2011 at 12:40 pm
Chonghai Hu
小弟来过,留个脚印。很牛,很好,很强大,沐兄加油!
04/16/2011 at 8:54 am
Mu
哈哈,小弟献丑,胡总见笑了
04/15/2011 at 12:42 pm
Chonghai Hu
这些鬼图都是你自己画的吗?大哥那个闲情逸致呀,不得不赞了先。
04/16/2011 at 8:56 am
Mu
前三章是shai的slides里偷,其余的自己画的。主要是最近赋闲,算是走前发光发热一把了
04/16/2011 at 11:32 am
lsws33
很不错的文章系列,希望沐兄继续更新下去,小弟还等着拜读您的大作
04/25/2011 at 3:36 pm
lsws33
请教下博主,每个时刻Wt为什么写成那种形式?Shai 在《Convex Repeated Games and Fenchel Duality》貌似也没有说明
04/28/2011 at 1:05 pm
Mu
wt就是一条向量,能够用来表示一大类模型
05/15/2011 at 5:04 pm
tiantian
分界面由w和b构成,b该如何表示呢
07/21/2011 at 4:48 pm
漫谈在线学习:阴阳论☯ | 增强视觉 | 计算机视觉 增强现实
[…] 继续转载limu童鞋的在线学习漫谈,地址 […]