
You are currently browsing the monthly archive for April 2011.
刚一条句子让wordpress bug了,拆成两篇算了
for的终极取代:多线程混合编程
我们也常会遇到并不能简答并行化的情形,例如针对数组元素的复杂的操作。这时的一个选择就是混合编程: mex, 它可以实现matlab与C/C++/Fortan之间的相互调用。matlab自带的user guide里有详细介绍。
在这里我们讨论两个小trick. 首先注意到向量化的高斯核代码中我们用到了exp(A),A可能是一个非常大的矩阵。而matlab却会不谙风情的先将这个大矩阵在内存里复制一次,然后再逐一算exp. 有时我们明明算好内存能存下,但matlab却报out of memory了。
我们可以用C来对内存进行直接操作。例如for(i...){A(i)=exp(A(i));}. 不过还有另外一个问题:现在我们计算机大多是多核多线程,matlab也很早就支持了多线程加速,而简单的for只会单线程,所以mex后的代码可能会慢很多。这时的我们的一个选择就是openmp,它为共享内存的多线程提供了非常方便的实现。
下面附上一计算exp(A)的多线程代码,它无需额外内存:
#include "mex.h"
#include
#include
#include
using namespace std;
void mexFunction( int nlhs, mxArray *plhs[],
int nrhs, const mxArray*prhs[] )
{
double *A, *pp;
mwSize n, m, p, i, j;
A = mxGetPr(prhs[0]);
n = mxGetN(prhs[0]); // # of rows in C
m = mxGetM(prhs[0]); // # of columns in C
p = omp_get_num_procs();
#pragma omp parallel for private (j) \
default(shared) num_threads(p)
for (i = 0; i < n; i ++) {
for (j = 0; j < m; j ++)
A[i*m+j] = exp(A[i*m+j]);
}
return;
}
编译时需要稍修改下编译参数来开启openmp的支持。例如linux下gcc需要加上flag-fopenmp,详见此说明,Windows下的visual studio的相应的flag是/openmp.
但用这段代码时需要很小心。matlab使用了lazy copy的技术,既当我们运行命令A=B时,matlab不会立即将B复制一份给A, 只有当A或者B被修改的时候才执行复制。如果我们用上面代码对B做指数运算,例如mex_exp(B), 这时matlab不知道B变了,所以复制还是不会执行,那么A就会和B一起被修改了,这也许会给后面的代码造成麻烦。
代码究竟慢在哪里
我们可以方便使用tic,toc来知道每段代码的执行时间。但要知道每条语句的详细运行情况的话,非profile莫属。
先运行profile on,再运行需要测试的代码,然后使用profile viewer来查看报告。例如,上面两段不同的计算高斯核的实现的profile报告如下(为了报告更有信息,将其中的一条长语句拆开成了三句)。


根据报告我们就知道每条语句的执行情况,从而可以对其中时间耗费最多的部分进行优化。
无止尽的优化
大多人类活动就是一优化过程。无论是金钱,利益,地位,还是算法,代码,编译,硬件。但除了最优化外,我们还追求一些其他。例如我们用matlab是为了实现和调试上的方便,虽然优化能让计算机做得更快,但是却花去了我们的工作时间,而且使得代码难读懂。糟糕的实现是大忌,过度的优化也不可取。所以,我们需要在计算时间,开发时间,代码的可读性之间做一个权衡。
前面一直在谈理论,为了避免成为纯理论blog, 这次聊聊最实验的部分:coding.
Matlab是数值计算和仿真中使用最为广泛的软件。它便捷,高效,通常可以直接将伪代码算法转换成matlab代码。但在方便的同时,matlab里面也有很多性能的陷阱。例如令人诟病的for语句。
在matlab里,至少有两种方法将一个数组每个元素加1. 一种来自一般的程序语言for i=1:length(a), a(i)=a(i)+1; end;另一种则借鉴数学记法a=a+1。
但在matlab中,这两实现的性能却有天壤之别。虽然matlab在不断优化for的执行,不过即使是matlab 2010b, 在我的笔记本上(Core 2 Duo 2.4 GHz, 4GB, Win7),对于一个10万元素的一维数组,第一种实现需5微秒,而第二种只用0.4微妙。后者快上10倍。
事实上,用过matlab就会发现,matlab自带的函数通常都有很高的性能。例如刚提到的a=a+1,或是排序 sort(a),以及令人称道的矩阵乘法,SVD分解等等。事实上,对于两矩阵a和b相乘,如果简单用三层for循环来实现(用C),性能肯定会比matlab差很多。
虽然matlab的界面是用java实现以方便跨平台,在性能上不尽人意,不过内核是用C实现的。可以试试命令matlab -nojvm。对于矩阵运算,matlab是调用高度优化的BLAS/LAPACK库。例如BLAS level3提供的一般矩阵乘法,它将矩阵拆成很多小块,充分利用内存的连续性,cpu的cache架构,多线程等来优化执行。matlab做的只是提供一个方便的人机接口。当然,其他函数例如sort matlab则提供自己优化过的实现。
但为什么用for时就会慢呢。主要原因是matlab是一种脚本语言,通过解释执行。每次我们运行一段代码时,matlab先预解析一遍,生成p-code, 然后一句一句执行。预解析当然是会有代价。在调用for时,matlab会每循环一次就会重新解析下for循环内部的代码,所以自然就慢了。
提高性能的办法是尽量使用matlab提供的函数,而非自己写。例如all(是否元素全非0), cumsum(累加), diff(相邻元素的差),prod(累乘)。另外一些小技巧包括预先通过zeros等操作分配内存。在这里我们着重讨论for的优化,通常称其为向量化(vectorizing)。
用bsxfun来取代for
bsxfun是一个matlab自版本R2007a来就提供的一个函数,作用是”applies an element-by-element binary operation to arrays a and b, with singleton expansion enabled.”
举个例子。假设我们有一列向量和一行向量。
a = randn(3,1), b = randn(1,3)
a =
-0.2453
-0.2766
-0.1913
b =
0.6062 0.5655 0.9057
我们可以很简单的使用matlab的外乘c=a*b来得到
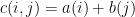
c=bsxfun(@plus,a,b)来实现。
bsxfun的执行是这样的,如果a和b的大小相同,那么c=a+b. 但如果有某维不同,且a或b必须有一个在这一维的维数为1, 那么bsxfun就将少的这个虚拟的复制一些来使与多的维数一样。在我们这里,b的第一维只有1(只一行),所以bsxfun将b复制3次形成一个3×3的矩阵,同样也将a复制成3×3的矩阵。这个等价于c=repmat(a,1,3)+repmat(b,3,1)。这里
repmat(a,1,3) ans = -0.2453 -0.2453 -0.2453 -0.2766 -0.2766 -0.2766 -0.1913 -0.1913 -0.1913
repmat是显式的复制,当然带来内存的消耗。而bsxfun是虚拟的复制,实际上通过for来实现,等效于for(i=1:3),for(j=1:3),c(i,j)=a(i)+b(j);end,end。但bsxfun不会有使用matlab的for所带来额外时间。实际验证下这三种方式
>> c = bsxfun(@plus,a,b)
c =
0.3609 0.3202 0.6604
0.3296 0.2889 0.6291
0.4149 0.3742 0.7144
>> c = repmat(a,1,3)+repmat(b,3,1)
c =
0.3609 0.3202 0.6604
0.3296 0.2889 0.6291
0.4149 0.3742 0.7144
>> for(i=1:3),for(j=1:3),c(i,j)=a(i)+b(j);end,end,c
c =
0.3609 0.3202 0.6604
0.3296 0.2889 0.6291
0.4149 0.3742 0.7144
从计算时间上来说前两种实现差不多,远高于for的实现。但如果数据很大,第二种实现可能会有内存上的问题。所以bsxfun最好。
这里@plus是加法的函数数柄,相应的有减法@minus, 乘法@times, 左右除等,具体可见 doc bsxfun.
下面看一个更为实际的情况。假设我们有数据A和B, 每行是一个样本,每列是一个特征。我们要计算高斯核,既
K1 = zeros(size(A,1),size(B,1));
for i = 1 : size(A,1)
for j = 1 : size(B,1)
K1(i,j) = exp(-sum((A(i,:)-B(j,:)).^2)/beta);
end
end
使用2,000×1,000大小的A和B, 运行时间为88秒。
考虑下面向量化后的版本:
sA = (sum(A.^2, 2)); sB = (sum(B.^2, 2)); K2 = exp(bsxfun(@minus,bsxfun(@minus,2*A*B', sA), sB')/beta);
使用同样数据,运行时间仅0.85秒,加速超过100倍。
如要判断两者结果是不是一样,可以如下
assert(all(all(abs(K1-K2)<1e-12)))
在高斯核中,我们通常可以取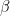
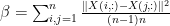
n = size(X,1); S = sum(X); beta = 2*norm(X,'fro')^2/(n-1) - (S*S')*2/n/(n-1);
各位有兴趣可以比比与for实现的性能差异,呵呵。
Primal-dual的观点
《红楼梦》第三一回云:天地间都赋阴阳二气所生。世间有阴便有阳,在优化界也是如此。我们将需要最小化的目标函数称之为primal problem. 其对应就有dual problem. 例如常见的Lagrange Duality. 如果primal是凸的,那么dual便是凹的。且在常见情况下,最小化primal等价于最大化dual. 有时候直接求解primal problem很麻烦,但dual却方便很多。或是通过考察dual problem的性质能得到最优解的一些性质。一个经典的案例就是SVM.
上节我们通过子空间投影
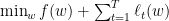

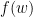
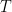
Shai Shalev-Shwartz提出可以用Fenchel Duality来研究其对偶式。Shai最近在online/stochastic界相当活跃。虽然和他不熟,不过因为他姓比较长,所以下面亲切的用Shai来称呼他。Shai 毕业于耶路撒冷希伯来大学,PHD论文便是online learning. 然后他去了online learning重地TTIC, 更是习得满身武艺,现在又回了耶路撒冷希伯来大学任教。他的数学直觉敏锐,善于将一些工具巧妙的应用到一些问题上。
两个概念
对一个凸函数,如下图所示,我们可以用两种不同的描述方式。一种就是函数上的所有点,函数曲线变由这些点构成;另外一种是每一个点所对应的切线,此时函数由所有切线形成的区域的上边缘确定。

函数上每一个点可由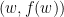
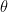
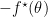
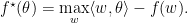
既然我们称它们为primal-dual, 当然意味着可以相互转换。实际上,对于一个闭凸函数,有

另外一个概念是关于函数凸的程度的。一个函数被称为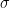


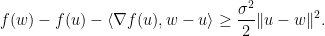
示意图如下。直观上来说就是这个凸函数要凸得足够弯。这个定义可以拓展到一般的范数和次导数上来处理诸如稀疏罚

Regret Bound分析
使用这两个概念可以得到一个重要定理。假设

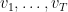
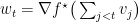
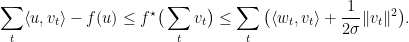
此定理可以为Boosting, learning theory里的Rademecher Bound提供简单的证明,不过我们先关注它在online上的应用。不等式两边左右移项得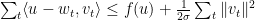
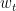
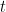
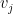
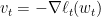
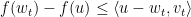

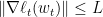

如果我们用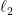

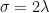
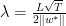

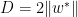
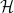
一般化的online算法
不小心先把理论讲完了,下面来解释下算法。接回一开始我们谈到的要考虑dual problem. 先观察到primal problem可以写成

引入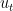
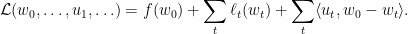
这样dual problem就是最大化函数
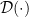

注意到与primal problem不同,这时罚里面的变量也被拆成了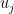
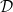
总结下算法。在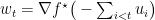

下面是一个示意图。在每个时间里我们根据新来的数据不断的增大dual, 同时使得primal变小。

一个值得讨论的是,在这里我们可以控制算法的aggressive的程度。例如,如果我们每次只取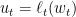

这个算法框架可以解释一系列算法,例如前面提到的Halving, 它使用激进步伐,或是WM, 使用平缓的步伐,以及Adaboost. 当然,我们可以从这个算法框架里推出新的有no-regret保证的新的online算法。
到这里,我们介绍的三个算法(前面是Online Gradient Descent, Weighted Majority)的regret bound都是

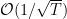
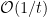
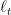

在线凸优化
回顾下上次聊的专家问题,在

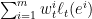
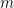

虽然WM的理论在上个世纪完成了[Littlestone 94, Freund 99],将其理论拓展到一般的凸的函数还是在03年由Zinkevich完成的。当时Zinkevich还是CMU的学生,现在在Yahoo! Research。话说Yahoo! Research的learning相当强大,Alex Smola(kernel大佬),John Langford(有个非常著名的blog),这些年在large scale learning上工作很出色。
回到正题。我们提到在online learning中learner遭受的累计损失被记成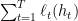


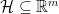
在线梯度下降
Zinkevich提出的算法很简单,在时刻

这里


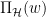
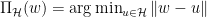
先来啰嗦几句其与离线梯度下降的区别。下图是一个区别示意图。在离线的情况下,我们知道所有数据,所以能计算得到整个目标函数的梯度,从而能朝最优解迈出坚实的一步。而在online设定下,我们只根据当前的数据来计算一个梯度,其很可能与真实目标函数的梯度有一定的偏差。我们只是减少

那online的优势在哪里呢?其关键是每走一步只需要看一下当前的一个数据,所以代价很小。而offline的算法每走一个要看下所有数据来算一个真实梯度,所以代价很大。假定有100个数据,offline走10步就到最优,而online要100步才能到。但这样offline需要看1000个数据,而online只要看100个数据,所以还是online代价小。
于是,我们很容易想到,offline的时候能不能每一步只随机抽几个数据点来算一个梯度呢?这样每一步代价就会很少,而且可能总代价会和online一样的少。当然可以!这被称之为Stochastic Gradient Descent,非常高效,下回再谈把。
在这里,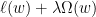


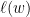
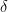

Regret Bound分析
记投影前的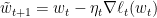
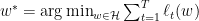
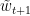



由于

取固定的


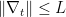
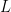
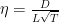
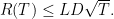
这个bound可以通过设置变动的学习率

Recent Comments